咨詢公司|成都企業管理咨詢公司|重慶企業管理咨詢公司|四川企業管理咨詢公司

咨詢公司|成都企業管理咨詢公司|重慶企業管理咨詢公司|四川企業管理咨詢公司
在這個大數據時代里面,使得人們看到了前所未有的世界關聯性:用人們購物的數據可以預測人們的喜好、朋友圈、社交圈,用人們的社交圈可以預測到他們的消費偏好,這一切的實現,沒有進行任何調查、設計、實驗、推理,而僅僅是讓沉沒的數據再次發出聲音。那么該如何讓沉默的人力資源數據說話呢?
在人力資源管理領域中,有哪些數據尚未得到充分利用?這些數據又可以進行哪些深度挖掘?又可以如何提升人力資源管理水平?下面將一一進行介紹。
在日常的人力資源管理中,有哪些數據可以被利用?根據數據收集和使用的特點分為以下幾種類型:
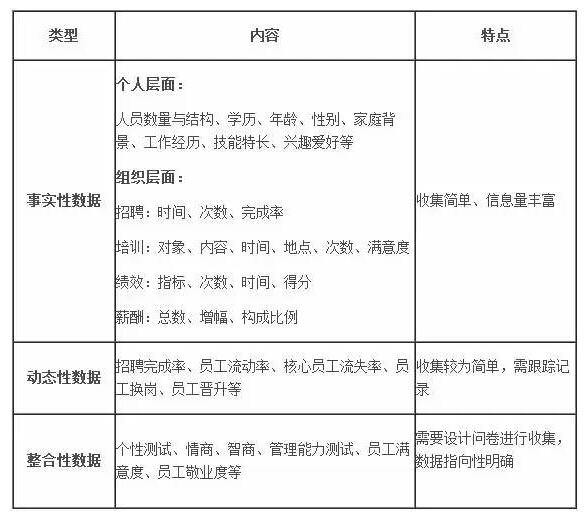
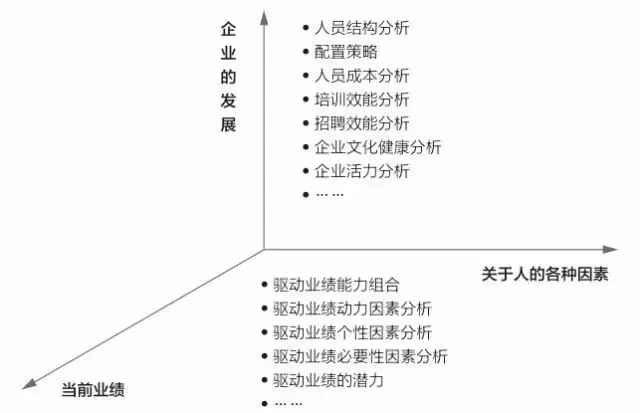
人力資源管理的最終目的是指向企業的長期發展和當前組織和個人績效的提升,數據利用的最終目的也應當是指向這兩個方向。圖中所示的三維圖(如下)展示的是人力資源各種數據可以應用的方向,為企業的發展和績效提升貢獻價值。
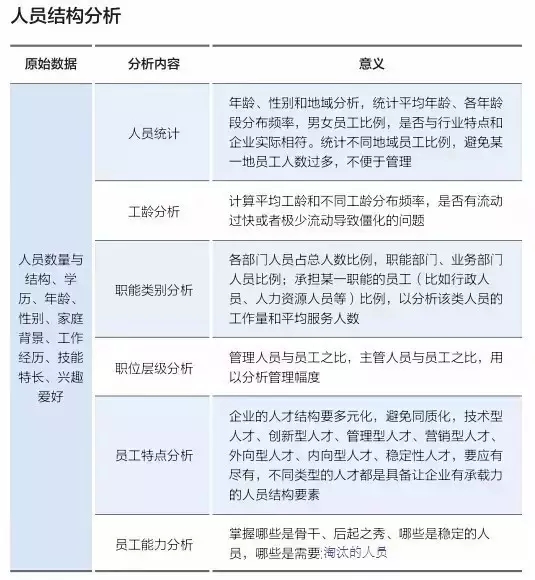
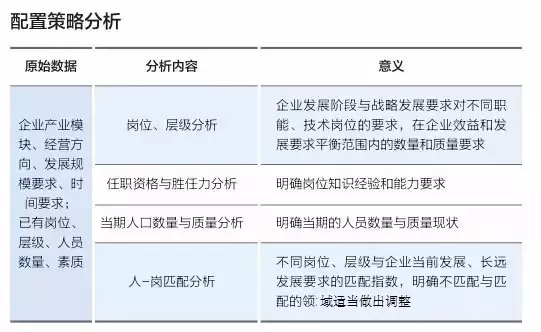
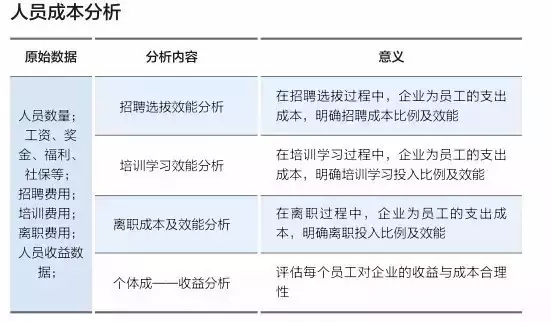
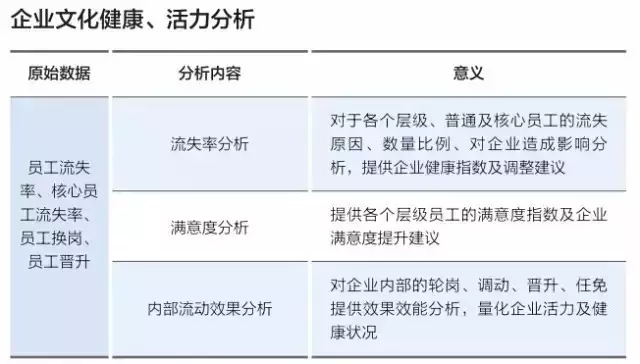
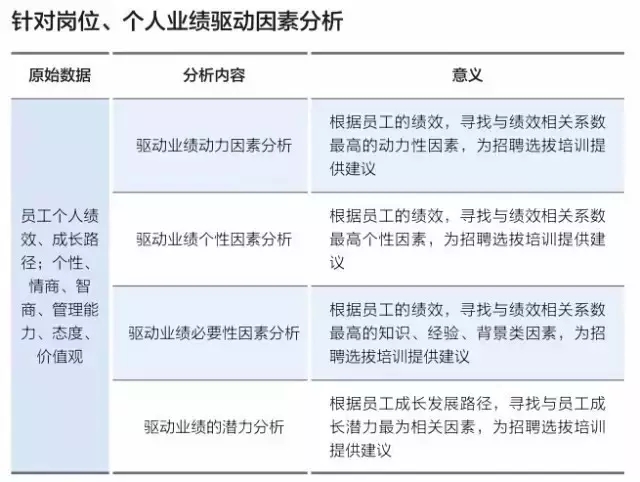
除此之外,有些數據本身需要通過進一步的統計處理,方能顯示它的真正含義,下面舉兩個簡單的例子進行說明。
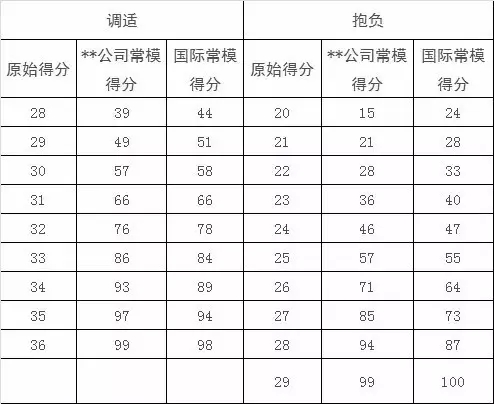
測驗所得的原始數據,只能表明受測者的得分,卻并不能表明該分數在人群中實際的水平如何,即使使用一些國際測驗會提供轉化后的分數,通常也是在全球的常模下的得分情況,如果企業想要知道受測者在本企業或者本行業的狀況,則需要獲取本企業或本行業的常模,方能得出比較準確的水平。下面是一個企業的心理測驗成績在全球常模和自己企業常模下的不同得分情況,可以看出,同一個分數,當與不同的常模做比較的時候,所得的分數是不同的,代表的水平也是不同的。
績效分數部分是由人主觀評價所得,這使得其分數本身就帶有了主觀性,有些分數實際上是不能直接使用的,需要進行進一步的加工處理,方能獲取數據真正的意義。例如在績效考核360評價的時候,評分者的尺度是存在差異的,有的人手松,有的人手緊,同一個人被不同人評價,也許得分會相差很大。但是,企業對于360數據的處理,通常是直接使用這些數據,有的時候會將這些不同人評價的分數權加之后進行排名,這樣操作是非常不合理的,很容易引起爭議。在實際處理中可以使用一些統計方法,例如標準分,來規避評分者評分尺度的差異,使得分數和排名真正反映出被評價者在評價者心目中的位置,這樣也能解決跨單位跨部門之間的比較問題。
標準化每個評價者的分數,使用到相同的平均分和標準差,統一評價者的尺度;
被評價者甲的總分=上級權重*上級標準分+平級權重*平級標準分+下級權重*下級標準分
數據分析建立的基礎是數據可靠、全面、連續,在這個基礎上建立起大數據分析或大數據的整合才有可能產生有價值的結論。但同時人力資源管理模塊眾多,從戰略規劃到招聘管理、培訓發展、績效管理、薪酬福利、員工關系、企業文化等等,需要進行數據分析的地方很多。但由于資源有限,要最大化的發揮人力資源分析的作用,在數據的收集和管理上,要注意以下事項。
● 從已有資源開始。人力資源管理部門手上有很多現成的數據,從這些數據入手,先一點點地做起來。數據本身不具備意義,關鍵在于如何將數據與人力資源業務關聯起來。這需要發揮創造性和能動性,并投入非常多的精力,需要掌握系統的基本統計方法。
● 堅持不懈。要有沉淀,一旦決定要做分析工作,就要將它融入人力資源管理的日常業務工作中去,并安排專人負責日常數據的收集與整理。并且這項工作一定要有持久性,任何一個時間斷面上的數據都難以單獨進行有效的分析。組織內部歷史數據的沉淀在評估和預測方面能發揮更大的作用。
● 打破常規,不斷創新。大數據時代的崛起,在于沒有拘泥于已有數據固有的意義,而是不斷尋找數據之間的關聯性,利用這種關聯性去預測和整合。思維、技術、數據是拉動數據分析的三輛馬車,其中思維是啟動機,一個良好的利用數據的模式和思路,是使用數據并進行創新管理的根本。
●“工欲善其事,必先利其器”,作為一名人力資源從業者,需要利用本崗位所擁有的資源,這些還在沉默的數據是進行精細化人力資源管理的好工具,并且這個工具一旦開始發揮作用,隨著時間和數據的累積,會逐漸成為指導企業成長和發展的人才風向標。
本文完,下篇為案例分析

作者:趙博
數據挖掘(Data Mining),又稱為數據庫中的知識發現(Knowledge Discovery in Database,KDD),就是從大量的、不完全的、有噪聲的、模糊的、隨機的實際應用數據中獲取有效的、新穎的、潛在有用的、最終可理解的模式的過程。簡單地說,數據挖掘就是從大量數據中提取或“挖掘”出有用的知識,從而幫助人們做出正確決策。
對于人力資源工作者而言,數據挖掘就是要在企業海量的人員數據、行為數據、經營數據和外部環境數據中進行深層分析,獲得有利于促進人才發展、提升人力資本效率、優化商業運作模型、提高核心競爭力的信息,從而支持人力資源政策乃至經營決策的制定。

數據挖掘說起來比較“高深”,但其實離我們并不遙遠。下面用M行的兩個實際案例簡要說明一下基于大數據的數據挖掘如何在人力資源管理活動中發揮作用。
1)問題提出
近年來,二級分行成為M行規模和利潤的增長點,如何更好地支持二級分行的高速發展是總行一直關注的議題。二級分行普遍反映其所在地人才相對匱乏,最有經驗、最有人脈資源的人才一般都在40-45歲,超出總行招聘的相應標準,人才引進難度較大。針對這個迫切的需求人力資源工作者應該如何處理?
2)數據整理與挖掘
為了回答上述問題,首先將各分行對公客戶經理的數據進行了整理,分別分析一級分行和二級分行對公客戶經理的特點,從而明確兩者是否應該采用差異化的政策標準。
從對公客戶經理在各經營機構的年齡分布情況看,60%-70%的對公客戶經理集中在25-35歲,且二級分行30歲以下人員占比較高。這說明二級分行年輕人更多,但這并不能證明二級分行優秀人才引進困難,如果這些年輕人在二級分行可以做得很好,那么也不必修改政策,應該鼓勵二級分行招聘年輕的客戶經理,用更低的成本開展工作。但事實情況如何?
進一步分析優秀客戶經理的分布情況。通過M行專業技術序列 評定為中級及以上的對公客戶經理基本上代表了經營機構的中堅力量,這部分人群在各機構的年齡分布出現了有意思的變化:二級分行中級及以上的對公客戶經理有50%以上都在35-45歲之間,而一級分行則是在25-35歲之間。這說明雖然二級分行25-35歲的人員較多,但真正業績突出的則是35-45歲的人員,而一級分行25-35歲的人員不僅數量較多,其綜合能力也較為突出。那到底是什么原因造成的?
進一步探討分行優秀客戶經理的特點。把學歷、行業經歷、專業經歷和入行經歷作為自變量,把客戶經理專業技術評定綜合得分作為因變量,用逐步帶入的方式進行回歸分析,看看不同經營機構影響客戶經理綜合得分的因素是什么。分析結果得出二級分行回歸方程為:綜合得分=69.83+0.663×專業經歷,R2(預測程度)= 0.213;一級分行回歸方程為:綜合得分=50.07+3.34×學歷+0.371×行業經歷,R2(預測程度)= 0.083
由此可見,在二級分行專業經歷顯著影響客戶經理綜合得分,這也部分印證了二級分行所在地干得好的客戶經理均是做工作經歷較長的人員。而在一級分行情況則不同,進入回歸方程的是學歷和行業經歷,說明在一級分行影響其綜合得分的因素較多,其中較高的學歷背景及較長的行業經驗成為客戶經理獲得成功的重要條件。
3)結果解讀與政策建議
通過上述的一系列分析可以看出,一級分行和二級分行優秀客戶經理的成功條件不同,二級分行可能還是更多地采用關系型營銷模式,而一級分行正在向專業型營銷模式轉變,因此在現階段制定招聘標準時可進行差異化設計。
在二級分行增加年齡的彈性。可以選取95分位作為臨界點,以便覆蓋95%的優秀客戶經理。經測算二級分行中級及以上客戶經理入行年齡的95分位值為41.35歲,一級分行為40.45歲。因此,可以分別以42歲和40歲作為招聘的參考標準。
在一級分行應堅持現有的學歷和年齡要求。針對一級分行均值差異檢驗表明,碩士研究生的業績顯著高于大學本科和大學專科,而大學本科和大學專科間無顯著性差異。因此可以通過大量引進碩士研究生進行系統培養,從而滿足未來的人才需求。
當然,以上的分析與建議均基于現狀,最后的政策還需要結合企業未來的人才規劃綜合考慮后制定。
1)問題提出
近年來同業間競爭日趨激烈,核心人才流失現象嚴重,各機構均反映剛培養起來的優秀員工很快就被別人挖走,這在一定程度上影響了M行業務的高速發展。那么,針對這樣棘手的問題人力資源工作者應該從何處入手避免核心人才流失?
2)數據整理與挖掘
對已參與專業技術序列評定的人員信息進行整理和分析,發現離職率最高的是C專業序列的人員,為8.89%,其他序列均在全行平均水平上下。因此,把C專業序列作為分析主體,盡量全的納入這個群體員工的各項信息,如性別、年齡、學歷、工作年限、入行年限、評定等級、行員等級變化等因素。采用Gini決策樹 計算方法,去探索影響C專業序列人員離職的因素。
通過計算各因素對離職率的影響系數,最終以行員等級是否變化、性別和評定層級作為樹節點繪制決策樹。
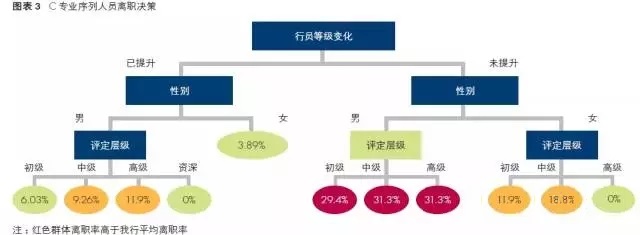
由圖3我們可以清晰的發現一些內在規律:兩年內行員等級得到提升的女員工離職率顯著低于全行平均水平;兩年內行員等級得到提升的男員工離職率處于全行平均水平上下,評定為中高級的人員離職率略微偏高,但也處于可控范圍內;兩年內行員等級未提升的女員工評定為中級及以下的出現了較高的離職現象;而兩年內行員等級未提升的男員工離職率大幅度提升,顯著高于全行平均水平,特別是評定為高級的人員,離職率達到37.5%。
3)結果解讀與政策建議
通過上述的分析可以看出,不同類別的群體存在差異巨大的離職傾向。各機構應關注離職高發群體,并制定差異化的留任計劃和政策。
例如應定期盤點員工發展情況,特別關注行員等級未提升的,且在專業技術評定中已獲得相應層級認可的男性員工。加強直接領導與高關注員工的溝通與交流,尋找阻礙員工發展的真實原因,根據具體原因采取針對性的措施:如員工發展目標不明確,則應及時描述發展目標和績效要求,為員工發展指明方向,待達到相應目標后及時進行激勵;如員工能力水平難以勝任現有崗位要求,則需要提供培訓學習機會,增加輔導和反饋,幫助員工快速提升專業能力;如員工工作態度或思想出現問題,則需進行開誠布公的溝通,及時解除思想包袱……同時,針對高關注員工存在的普遍問題,還需研究制定或修訂相應的政策制度,使其更能符合企業和員工的需求,激發員工動力。
如此一來,不僅能從前端盡可能地抑制離職行為的發生,防患于未然。同時還能化解一些潛在的問題和矛盾,激發員工的工作熱情,進一步提升整體績效表現。
上述兩個案例只是數據挖掘的一些簡單應用,但其分析結果所能帶來的價值已經證明了數據挖掘在人力資源管理中的巨大潛力。那么,如何快速彌補人力資源工作者在數據挖掘方面的能力斷層呢?筆者認為可以從以下幾個步驟進行嘗試:
第一、培養數據意識,用數據說話
首先,人力資源工作者應培養起數據意識。在日常工作中有意識地建立并積累有關人力資源管理活動的數據,在人力資源預測和決策時盡量用數據說話,營造出人力資源數據氛圍。但要注意,數據分析的目的是解決實際問題,不能流于形式,為數據而數據,那樣將會起到相反的效果。
第二、從某個領域開始,從描述統計開始
其次,人力資源工作者應認真盤點自己現有的數據資源。先從某個領域開始,特別是要從能為業務提供高價值的領域開始,嘗試采用各種基礎的統計方法和展現形式去描述現狀。有時候,只是簡單的描述出現狀已經可以獲得很多有價值的信息。
第三、從描述統計到推論統計
然后,人力資源工作者要不斷提升自己的數據分析能力。在描述統計的基礎上,對未知數量特征做出以概率形式表述的推論,去探索現象背后的原因,逐步實現從描述統計到推論統計的升華。當然,在這一部分,作為人力資源工作者更多地是深刻理解各種統計模型的原理,知道其能實現什么樣的分析功能,具體的數據挖掘完全可以借助專業的第三方來完成。
第四、從預測到決策
最后,人力資源工作者需要從業務需求出發、從組織戰略出發,制定大數據開發計劃,有機結合預測結果與業務發展實際,正確解釋和運用數據挖掘結果,為企業的最優決策提供依據。
借用大數據時代的經典語錄:“誰掌握數據,誰就將掌握未來!”在日新月異的新經濟時代,人力資源工作者也將通過掌控人力資源大數據,不斷提升人力資源管理的科學性和公信力,在未來為企業的持續發展做出更大的貢獻。
想了解更多信息,請關注成都明德管理咨詢公司(http://www.kikusui-gakuen.com/),明德管理咨詢機構是一家全國性的管理咨詢公司,擁有北京管理咨詢公司,成都管理咨詢公司和重慶管理咨詢公司三地機構,專注結局戰略規劃、組織運營和人力資源的專業管理咨詢。




 400 6900 328
400 6900 328



